Constrained Decoding¶
Constrained decoding is a technique used by XGrammar to generate structured outputs.
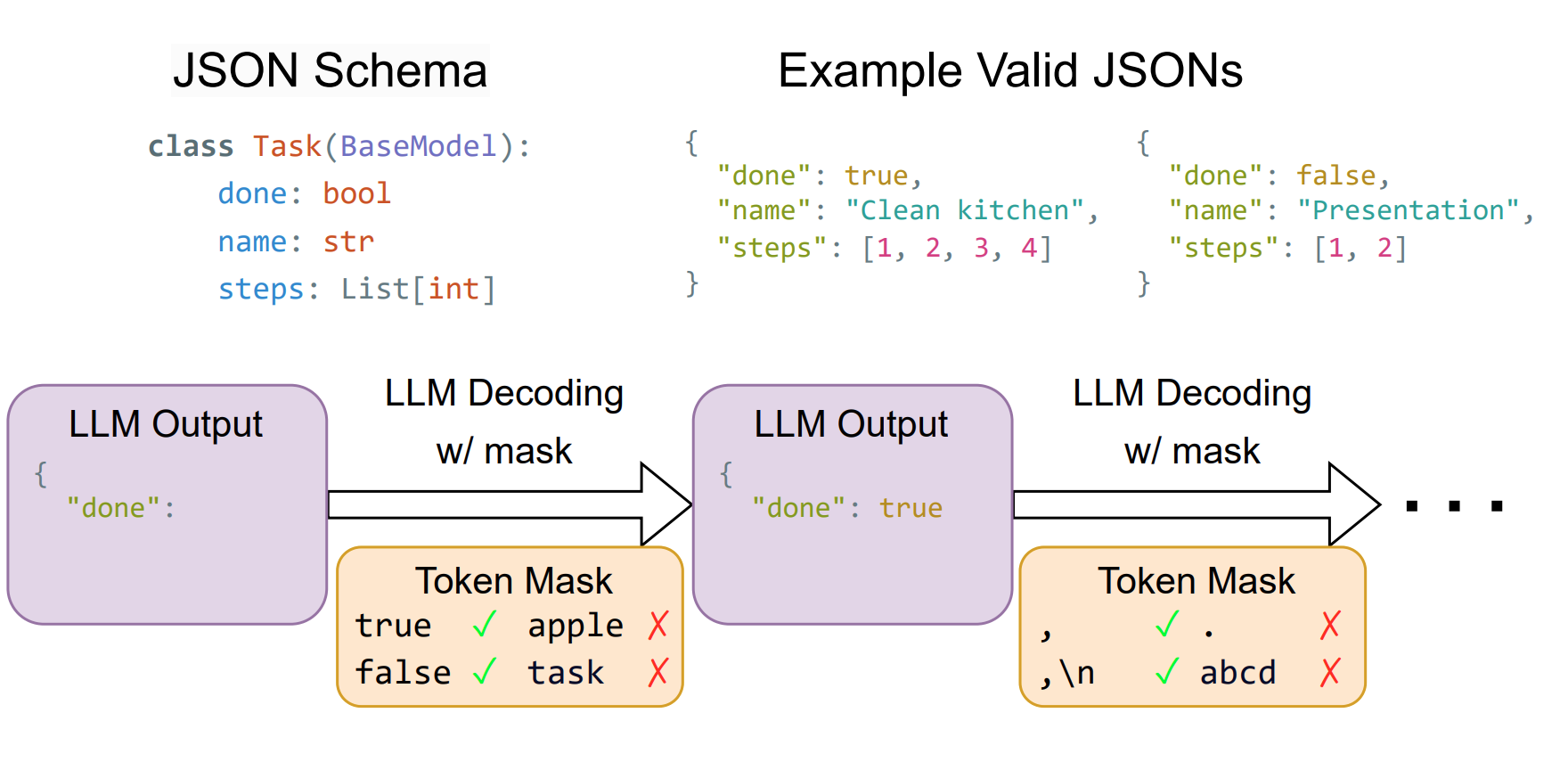
In each step of LLM inference, XGrammar will provide a token mask to the LLM. The mask allows the LLM to generate tokens that follow the grammar, and prohibits those not. The mask is a binary mask of the same length as the vocabulary size. In the sampling stage of LLM inference, the mask is used so that the sampled tokens must be valid in the mask.
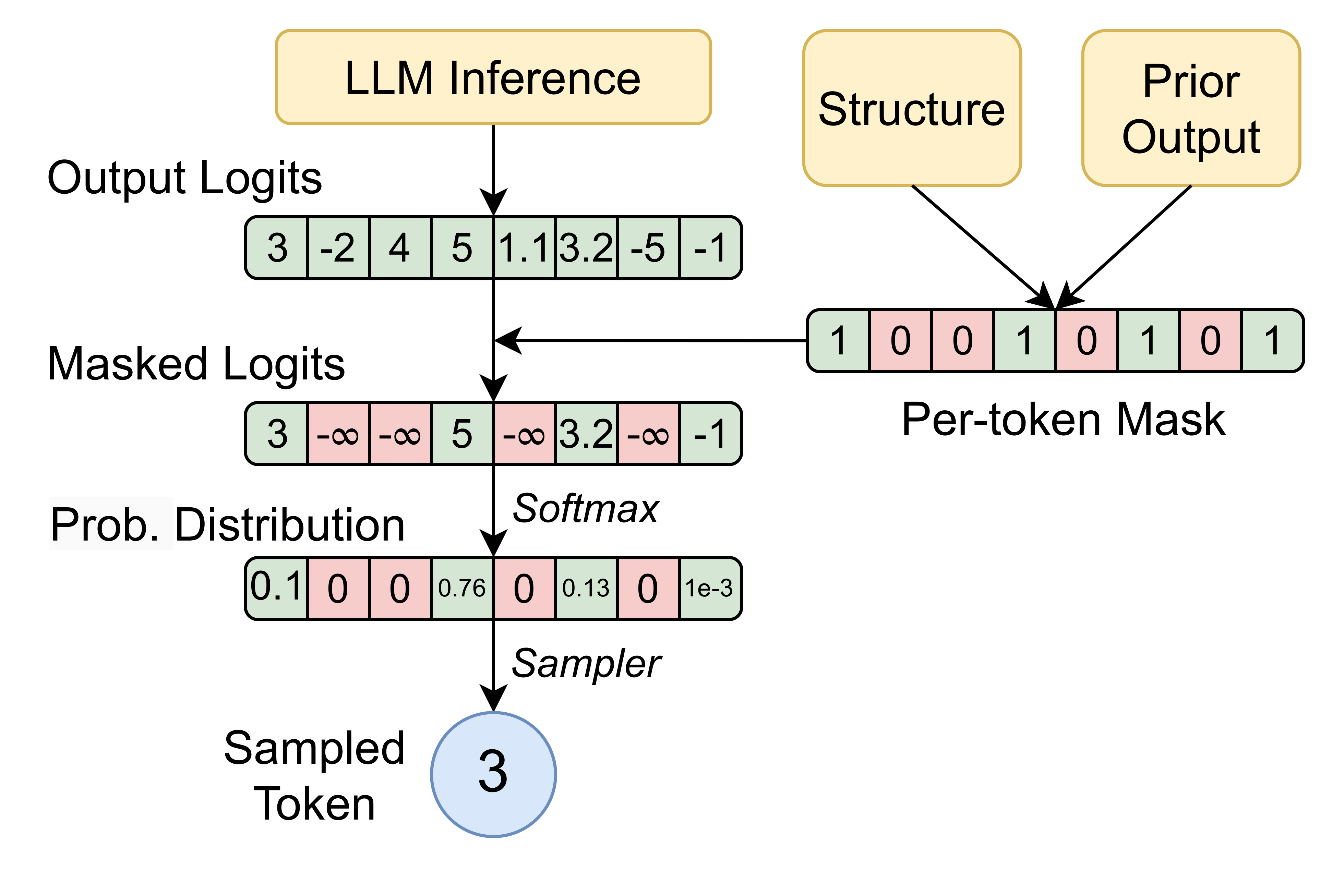
Let’s take a closer look. The binary mask applies to the logits of the LLM. It sets the logits of the tokens that are not allowed to \(-\infty\), so that their probability will be \(0\) after softmax. Then the sampler will sample from the vaild tokens with probability \(>0\).
By ensuring that each token generated by the LLM conforms to the given structure step by step, we can guarantee that the entire generation adheres to the specified structure.
Constrained decoding provides these benefits to LLM applications:
Increase generation quality. Sometimes an LLM can generate output that is nearly correct but makes mistakes in the details. For example, it might output a JSON integer field like 1.23 as a string (“1.23”), or even get the type completely wrong. Constrained decoding can ensure the output always follow the given structure.
Easy to parse and process. Constrained decoding ensures that the output of the LLM is clean, without extraneous text or syntax errors. This makes its output directly parsable and seamlessly integrable with downstream applications.
Ensure safety and avoid unexpected outputs. We can control the content generated by the LLM to prevent unexpected erroneous outputs. There have been many recent reports about safety issues in agent applications, and the ability to ensure the correctness of generated content is especially valuable for today’s agent use cases.
Constrained decoding has minimal negative impact on LLM generation. This is because if the LLM is already capable of generating correct responses, applying constraints doesn’t do anything. But if the LLM fails to produce a correct answer, the constraints can at least ensure the structure is correct.
Note: when applying constrained decoding, it is recommended to also describe the expected output structure in the prompt. This is because constrained decoding only affects the sampling stage, but we want the LLM’s underlying probability distribution to already align with the structure as much as possible.
XGrammar’s Implementation¶
In XGrammar, we store the token mask in a compressed bitset format using int32. Use xgr.allocate_token_bitmask to allocate a token mask.
XGrammar uses xgr.Grammar to describe the output structure (or, the grammar). It has a compilation step of the grammar to speed up the generation of the mask. The xgr.GrammarCompiler class compiles a xgr.Grammar object into a xgr.CompiledGrammar object.
The xgr.GrammarMatcher class, constructed from a xgr.CompiledGrammar object, is used to generate the mask. It is a stateful class that can be used to generate the mask for a single step of the generation. For each step, it will accept the last token generated by the LLM with xgr.GrammarMatcher.accept_token, and then generate the mask with xgr.GrammarMatcher.fill_next_token_bitmask. Then the mask can be used to guide the sampling of the next token.
Next Steps¶
See Workflow of XGrammar to learn more about the constrained decoding process.